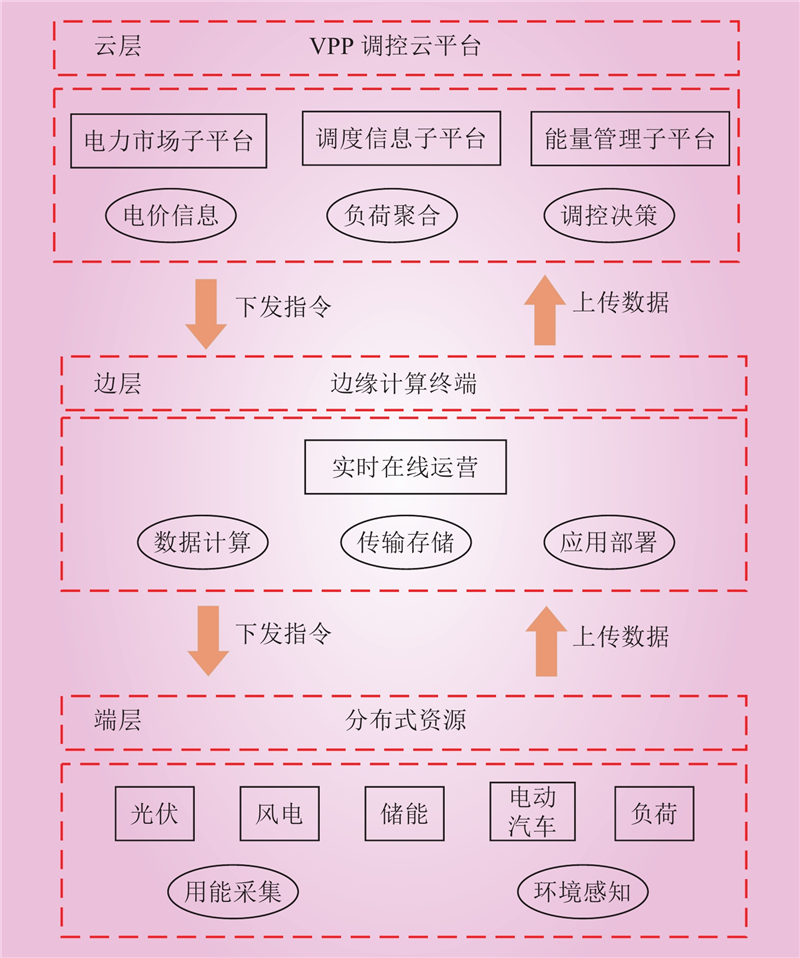
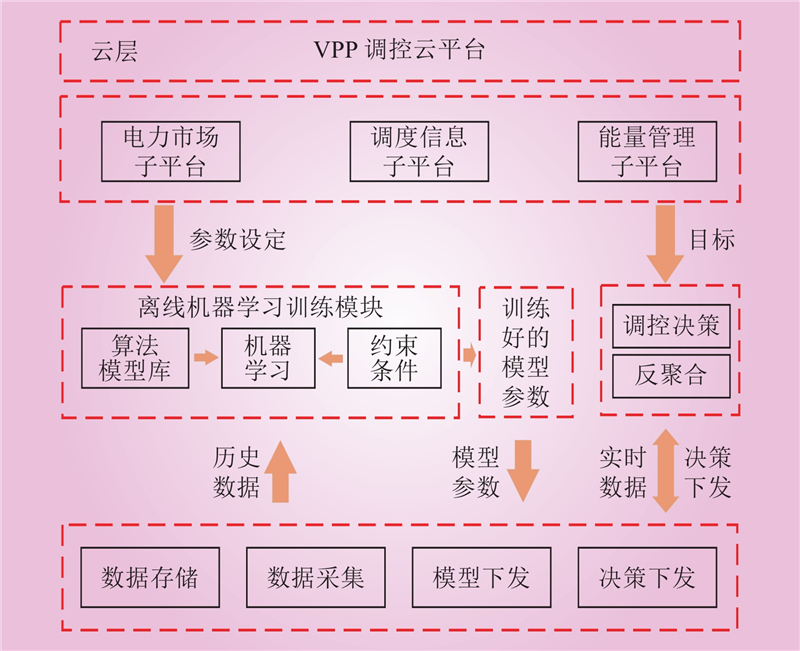
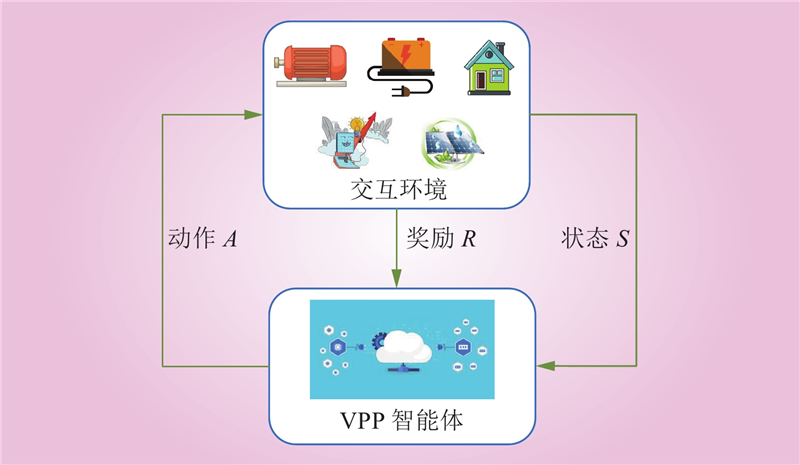
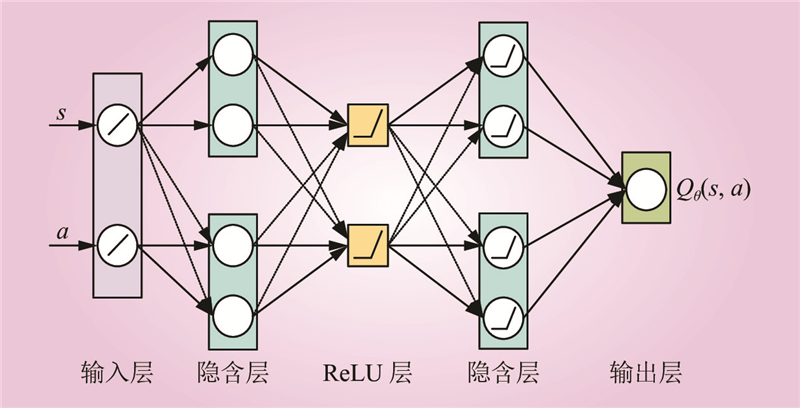
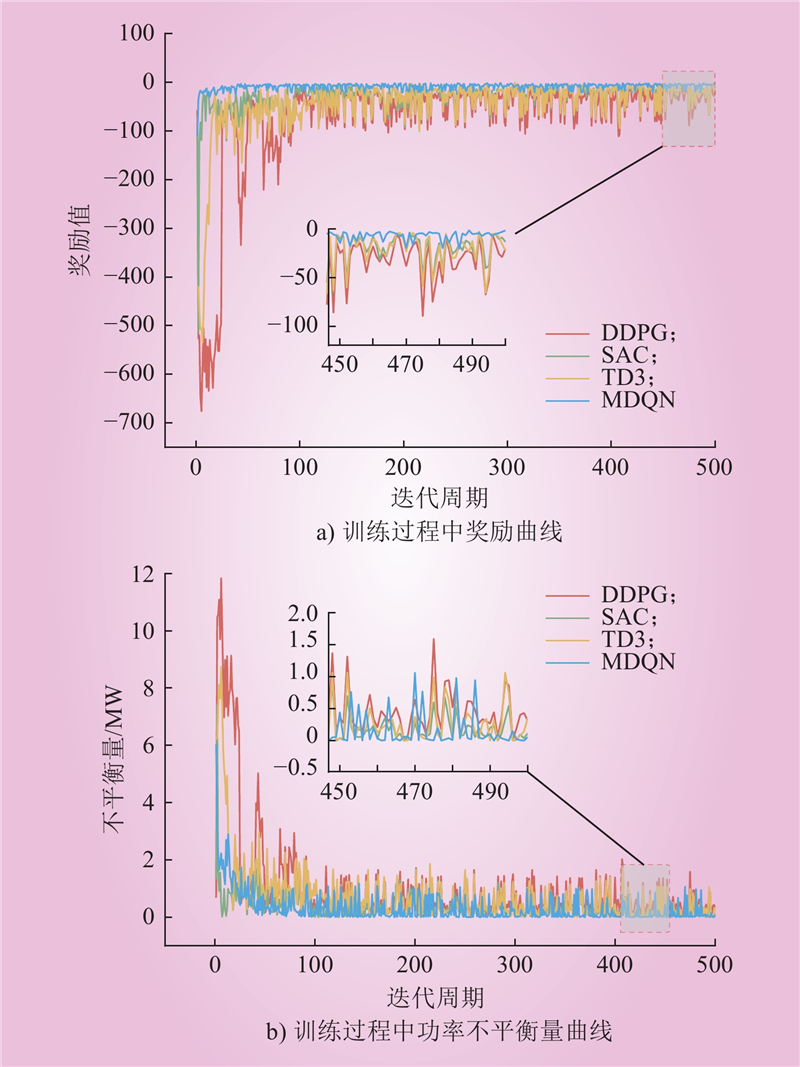
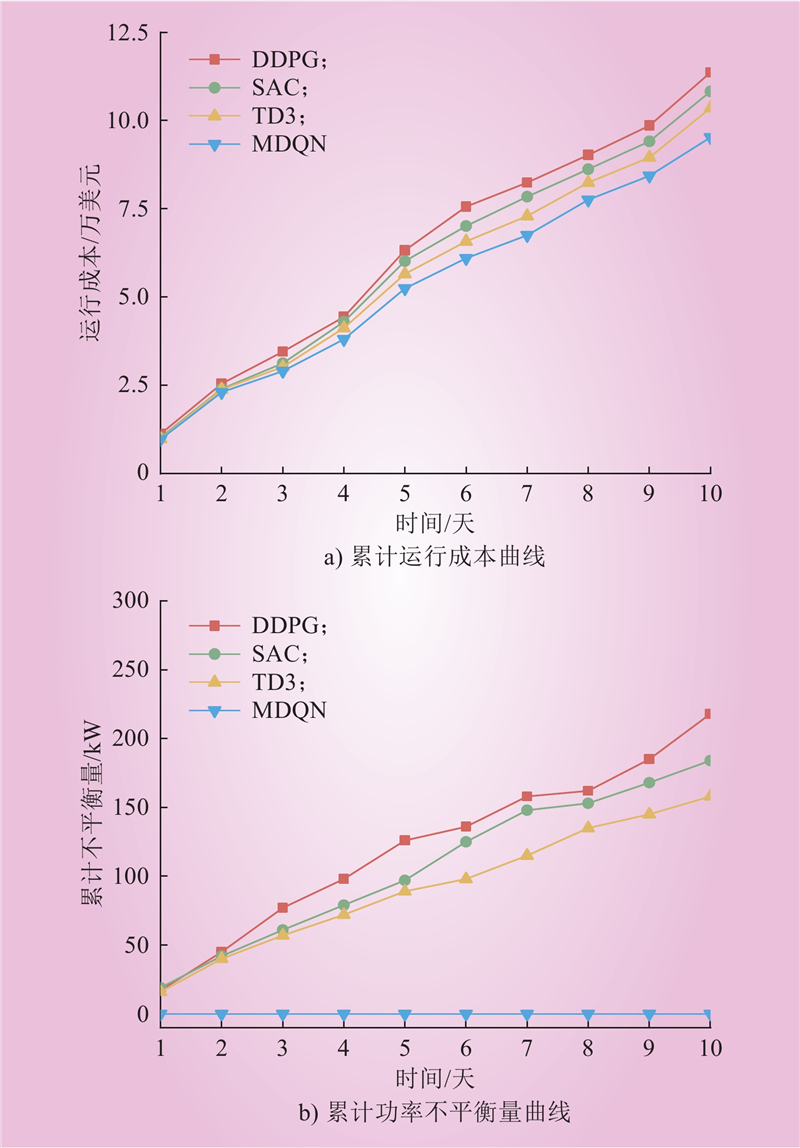
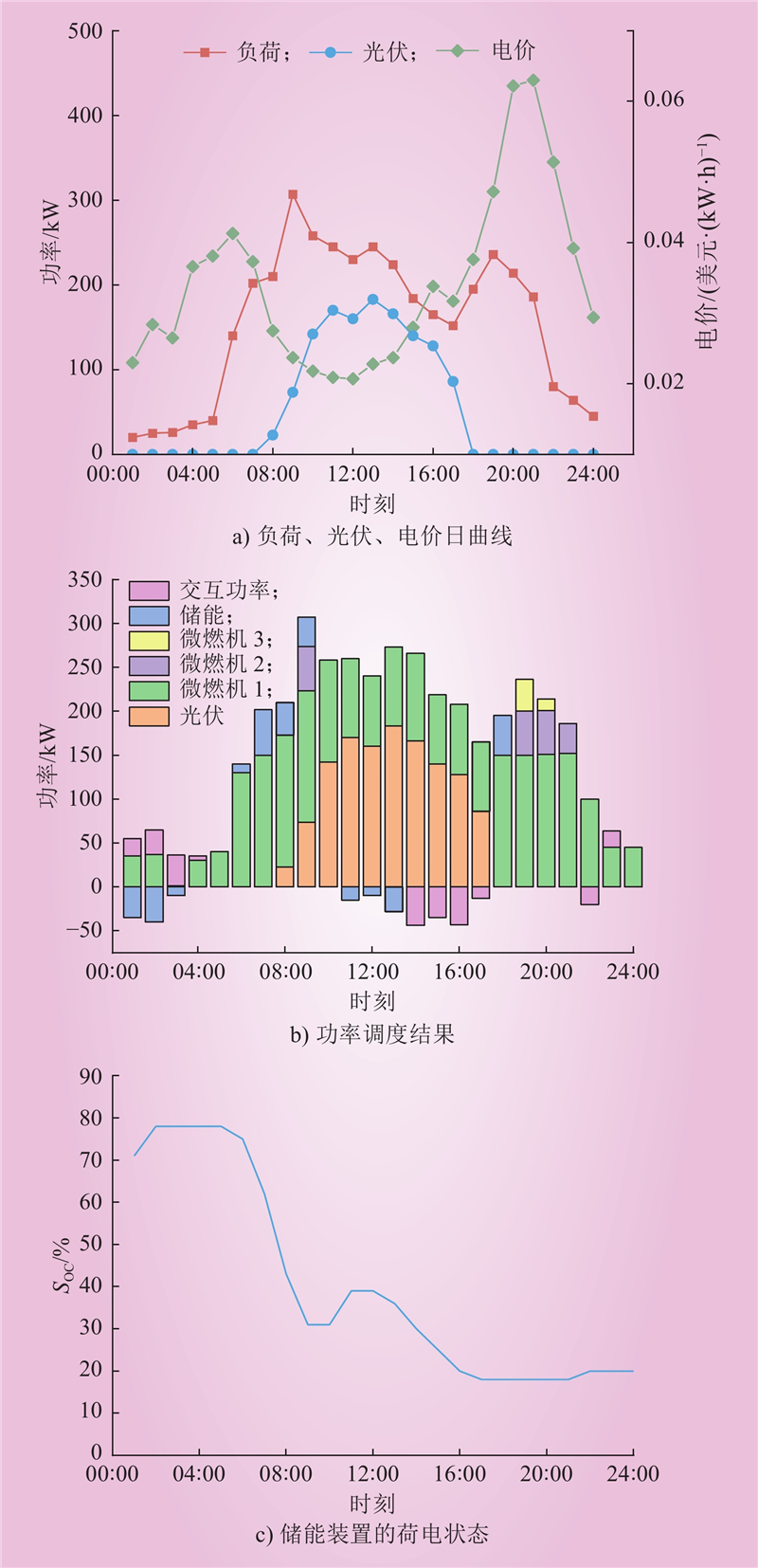
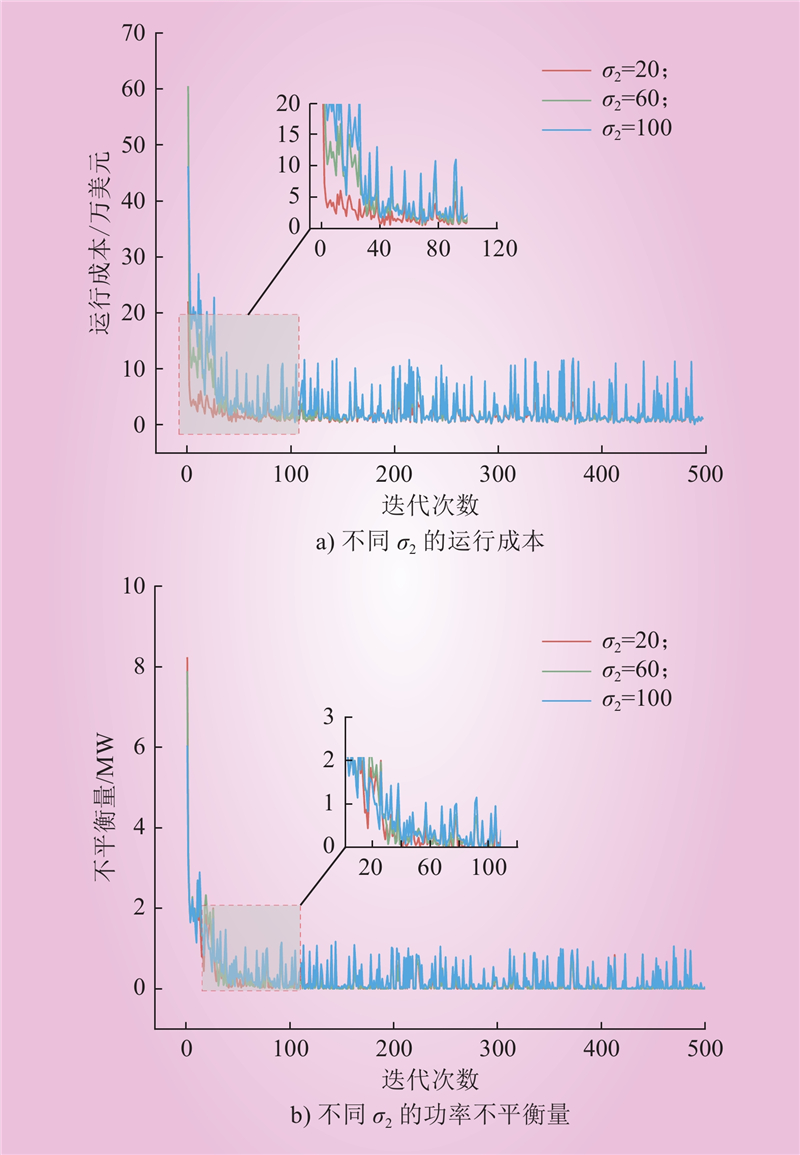
| 1 |
林毓军, 苗世洪, 杨炜晨, 等. 面向多重不确定性环境的虚拟电厂日前优化调度策略[J]. 电力自动化设备, 2021, 41 (12): 143- 150.
|
|
LIN Yujun, MIAO Shihong, YANG Weichen, et al. Day-ahead optimal scheduling strategy of virtual power plant for environment with multiple uncertainties[J]. Electric Power Automation Equipment, 2021, 41 (12): 143- 150.
|
| 2 |
尚文强, 李广磊, 丁月明, 等. 考虑源荷不确定性和新能源消纳的综合能源系统协同调度方法[J/OL]. 电网技术: 1–17.[2023-10-23]. https: //doi. org/10.13335/j. 1000-3673. pst. 2023.0577.
|
|
SHANG Wenqiang, LI Guanglei, DING Yueming, et al. A collaborative dispatching method for comprehensive energy systems considering source load uncertainty and new energy consumption [J/OL]. Power System Technology: 1–17[2023-10-23].https://doi.org/10.13335/j.1000-3673.pst.2023.0577.
|
| 3 |
陶力, 杨夏喜, 顾金辉, 等. 基于SAC和TD3的含电动汽车虚拟电厂调度策略[J]. 电气传动, 2023, 53 (9): 25- 34.
|
|
TAO Li, YANG Xiaxi, GU Jinhui, et al. Scheduling strategy of virtual power plant with electric vehicle based on SAC and TD3[J]. Electric Drive, 2023, 53 (9): 25- 34.
|
| 4 |
CHEN C S, XIAO L L, DUAN S D, et al. Cooperative optimization of electric vehicles in microgrids considering across-time-and-space energy transmission[J]. IEEE Transactions on Industrial Electronics, 2019, 66 (2): 1532- 1542.
|
| 5 |
程逸帆, 乔飞, 侯珂, 等. 区域微电网群两级能量调度策略优化研究[J]. 仪器仪表学报, 2019, 40 (5): 68- 77.
|
|
CHENG Yifan, QIAO Fei, HOU Ke, et al. Research on bi-level energy dispatching strategy optimization for regional microgrid cluster[J]. Chinese Journal of Scientific Instrument, 2019, 40 (5): 68- 77.
|
| 6 |
梁涛, 孙博峰, 谭建鑫, 等. 基于深度强化学习算法的风光互补可再生能源制氢系统调度方案[J]. 高电压技术, 2023, 49 (6): 2264- 2275.
|
|
LIANG Tao, SUN Bofeng, TAN Jianxin, et al. Scheduling scheme of wind-solar complementary renewable energy hydrogen production system based on deep reinforcement learning[J]. High Voltage Engineering, 2023, 49 (6): 2264- 2275.
|
| 7 |
王尧, 樊伟, 王佳伟, 等. 考虑风光不确定性的分布式能源集成虚拟电厂收益-风险均衡模型[J]. 可再生能源, 2020, 38 (1): 76- 83.
|
|
WANG Yao, FAN Wei, WANG Jiawei, et al. Revenue-risk equilibrium model for distributed energy integrated virtual power plant benefits considering wind and light uncertainty[J]. Renewable Energy Resources, 2020, 38 (1): 76- 83.
|
| 8 |
LI Z M, XU Y. Temporally-coordinated optimal operation of a multi-energy microgrid under diverse uncertainties[J]. Applied Energy, 2019, 240, 719- 729.
|
| 9 |
罗建勋, 张玮, 王辉, 等. 基于深度强化学习的微电网优化调度研究[J]. 电力学报, 2023, 38 (1): 54- 63.
|
|
LUO Jianxun, ZHANG Wei, WANG Hui, et al. Research on optimal scheduling of micro-grid based on deep reinforcement learning[J]. Journal of Electric Power, 2023, 38 (1): 54- 63.
|
| 10 |
郭庆来, 兰健, 周艳真, 等. 基于混合智能的新型电力系统运行方式分析决策架构及其关键技术[J]. 中国电力, 2023, 56 (9): 1- 13.
|
|
GUO Qinglai, LAN Jian, ZHOU Yanzhen, et al. Architecture and key technologies of hybrid-intelligence-based decision-making of operation modes for new type power systems[J]. Electric Power, 2023, 56 (9): 1- 13.
|
| 11 |
石文喆, 李冰洁, 尤培培, 等. 基于深度强化学习的建筑能源系统优化策略[J]. 中国电力, 2023, 56 (6): 114- 122.
|
|
SHI Wenzhe, LI Bingjie, YOU Peipei, et al. Optimization strategy of building energy system based on deep reinforcement learning[J]. Electric Power, 2023, 56 (6): 114- 122.
|
| 12 |
蔺伟山, 王小君, 孙庆凯, 等. 不确定性环境下基于深度强化学习的综合能源系统动态调度[J]. 电力系统保护与控制, 2022, 50 (18): 50- 60.
|
|
LIN Weishan, WANG Xiaojun, SUN Qingkai, et al. Dynamic dispatch of an integrated energy system based on deep reinforcement learning in an uncertain environment[J]. Power System Protection and Control, 2022, 50 (18): 50- 60.
|
| 13 |
刘林鹏, 朱建全, 陈嘉俊, 等. 基于柔性策略-评价网络的微电网源储协同优化调度策略[J]. 电力自动化设备, 2022, 42 (1): 79- 85.
|
|
LIU Linpeng, ZHU Jianquan, CHEN Jiajun, et al. Cooperative optimal scheduling strategy of source and storage in microgrid based on soft actor-critic[J]. Electric Power Automation Equipment, 2022, 42 (1): 79- 85.
|
| 14 |
ALI K H, ABUSARA M, ALI TAHIR A, et al. Dual-layer Q-learning strategy for energy management of battery storage in grid-connected microgrids[J]. Energies, 2023, 16 (3): 1334.
|
| 15 |
张宏涛, 吴怡之, 邓开连, 等. 一种基于强化学习的微电网能量管理算法[J]. 物联网技术, 2022, 12 (12): 74- 78.
|
| 16 |
CHEN P Z, LIU M C, CHEN C X, et al. A battery management strategy in microgrid for personalized customer requirements[J]. Energy, 2019, 189, 116245.
|
| 17 |
吴利刚, 张梁, 周倩, 等. 基于强化学习的微电网能量调度优化策略研究[J]. 控制工程, 2022, 29 (7): 1162- 1172.
|
|
WU Ligang, ZHANG Liang, ZHOU Qian, et al. Research on energy scheduling optimization strategy of micro-grid based on reinforcement learning[J]. Control Engineering of China, 2022, 29 (7): 1162- 1172.
|
| 18 |
马苗苗, 董利鹏, 刘向杰. 基于Q-learning算法的多智能体微电网能量管理策略[J]. 系统仿真学报, 2023, 35 (7): 1487- 1496.
|
|
MA Miaomiao, DONG Lipeng, LIU Xiangjie. Energy management strategy of multi-agent microgrid based on Q-learning algorithm[J]. Journal of System Simulation, 2023, 35 (7): 1487- 1496.
|
| 19 |
冯斌, 胡轶婕, 黄刚, 等. 基于深度强化学习的新型电力系统调度优化方法综述[J]. 电力系统自动化, 2023, 47 (17): 187- 199.
|
|
FENG Bin, HU Yijie, HUANG Gang, et al. Review on optimization methods for new power system dispatch based on deep reinforcement learning[J]. Automation of Electric Power Systems, 2023, 47 (17): 187- 199.
|
| 20 |
张华赢, 艾精文, 汪伟. 基于约束型深度强化学习的主动配电网电压控制策略[J]. 电测与仪表, 2023, 60 (5): 159- 166.
|
|
ZHANG Huaying, AI Jingwen, WANG Wei. Volt/Var control strategy for active distribution network based on constrained deep reinforcement learning[J]. Electrical Measurement & Instrumentation, 2023, 60 (5): 159- 166.
|
| 21 |
朱卉乔, 王卫东. 网络拥塞控制的优化研究[J]. 保密科学技术, 2022, (5): 56- 60.
|
| 22 |
胡维昊, 曹迪, 黄琦, 等. 深度强化学习在配电网优化运行中的应用[J]. 电力系统自动化, 2023, 47 (14): 174- 191.
|
|
HU Weihao, CAO Di, HUANG Qi, et al. Application of deep reinforcement learning in optimal operation of distribution network[J]. Automation of Electric Power Systems, 2023, 47 (14): 174- 191.
|
| 23 |
陈兴国, 孙丁源昊, 杨光, 等. 不动点视角下的强化学习算法综述[J]. 计算机学报, 2023, 46 (6): 1246- 1271.
|
|
CHEN Xingguo, SUN Dingyuanhao, YANG Guang, et al. A survey of reinforcement learning algorithms from a fixed point perspective[J]. Chinese Journal of Computers, 2023, 46 (6): 1246- 1271.
|
| 24 |
FISCHETTI M, JO J. Deep neural networks and mixed integer linear optimization[J]. Constraints, 2018: 296–309.
|