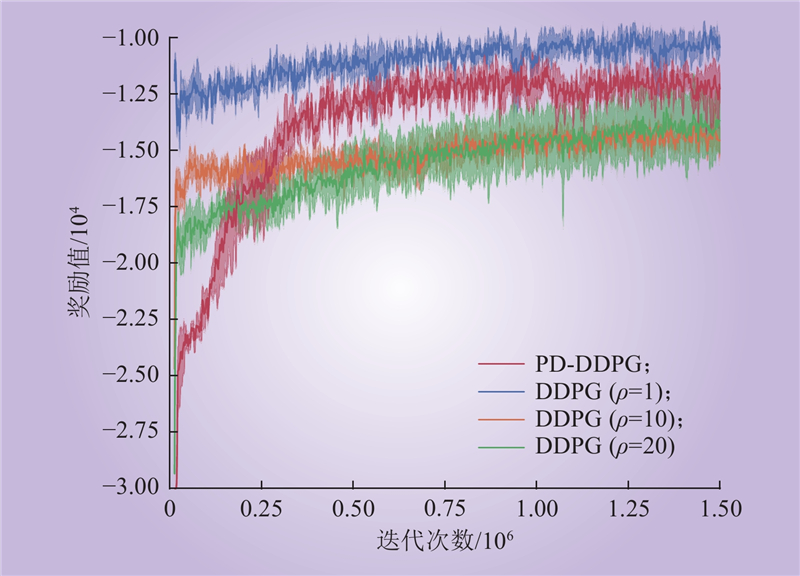
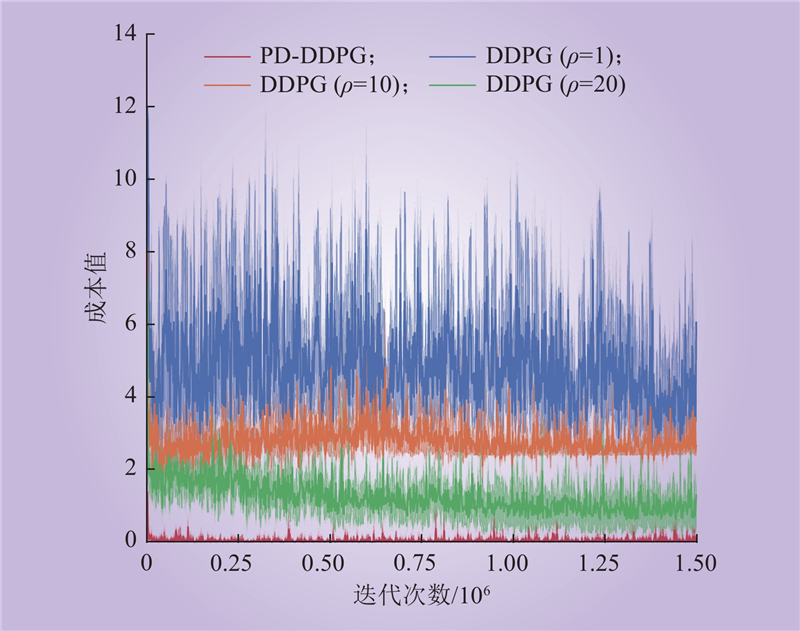
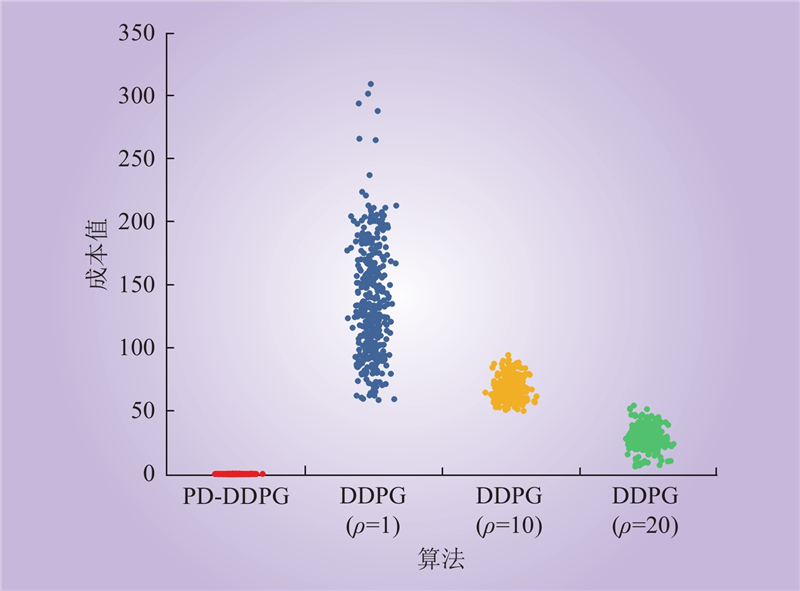
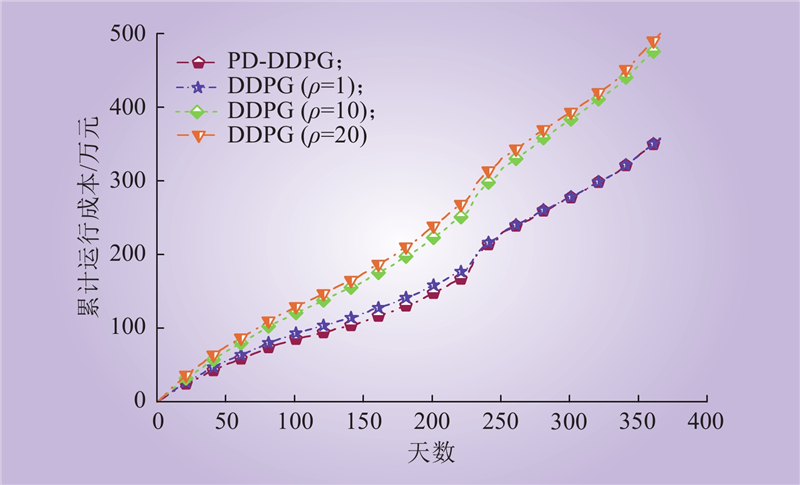
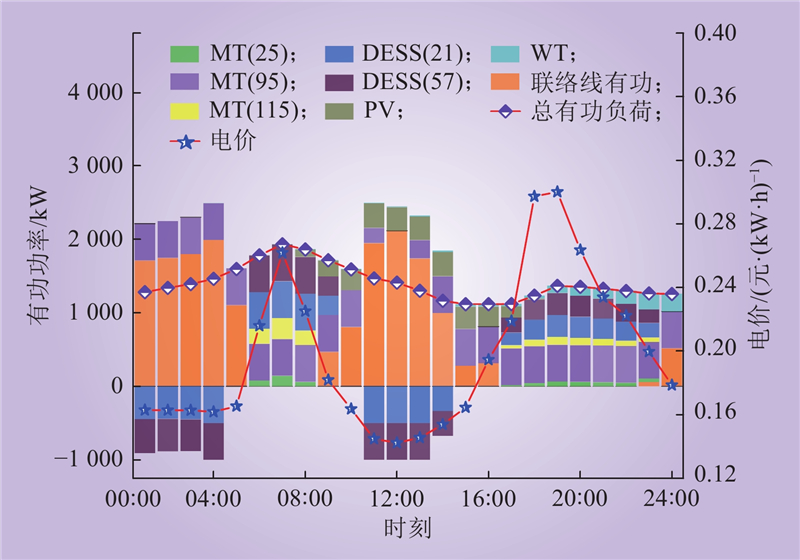
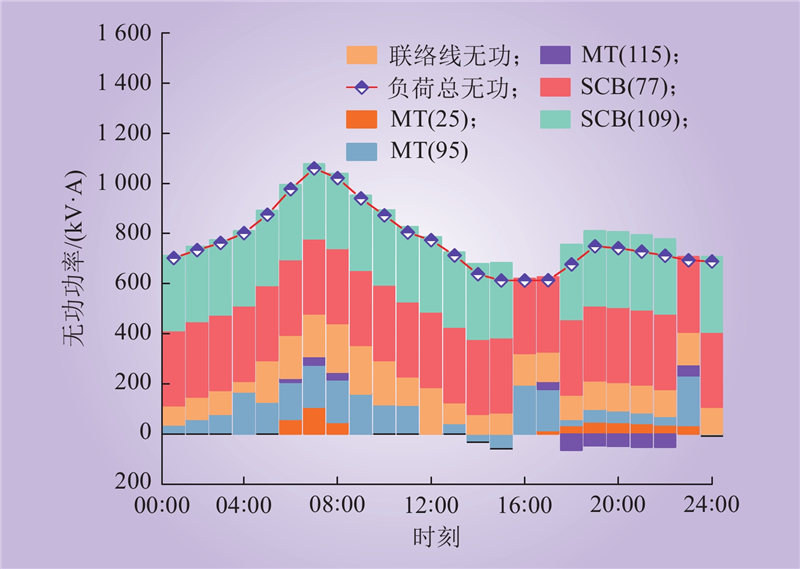
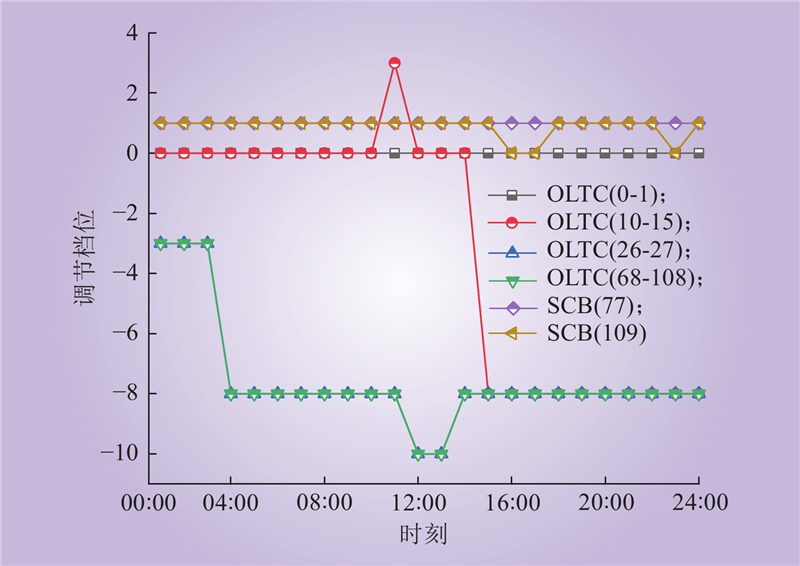
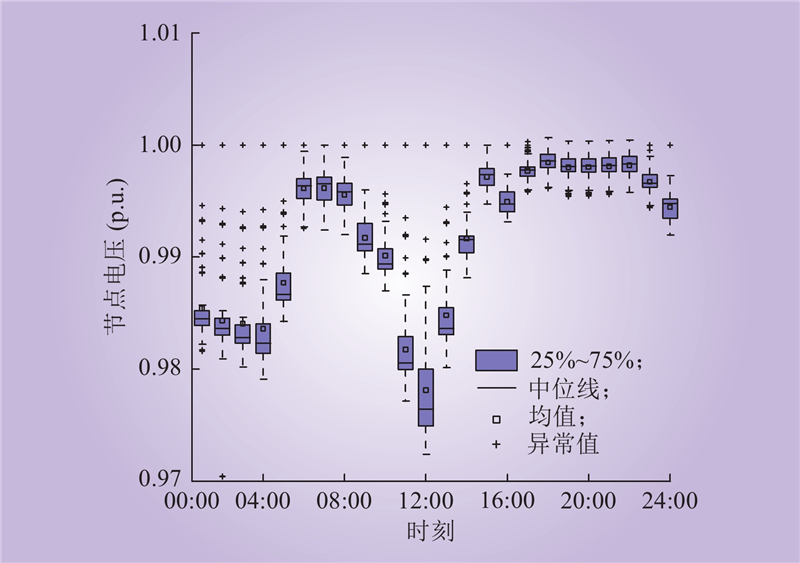
| 1 |
王鹤, 王钲淇, 韩皓, 等. 使用蒙特卡罗逐时估算模型的住宅配电网光伏准入容量研究[J]. 东北电力大学学报, 2023, 43 (1): 9- 19, 2, 99.
|
|
WANG He, WANG Zhengqi, HAN Hao, et al. Research on photovoltaic hosting capacity of residential distribution network based on Monte Carlo hourly estimation framework[J]. Journal of Northeast Electric Power University, 2023, 43 (1): 9- 19, 2, 99.
|
| 2 |
丁琦欣, 覃洪培, 万灿, 等. 基于机会约束规划的配电网分布式光伏承载能力评估[J]. 东北电力大学学报, 2022, 42 (6): 28- 38.
|
|
DING Qixin, QIN Hongpei, WAN Can, et al. Chance-constrained optimization-based distributed photovoltaic hosting capacity assessment of distribution networks[J]. Journal of Northeast Electric Power University, 2022, 42 (6): 28- 38.
|
| 3 |
杨亘烨, 孙荣富, 丁然, 等. 计及光伏多状态调节能力的配电网多时间尺度电压优化[J]. 中国电力, 2022, 55 (3): 105- 114.
|
|
YANG Genye, SUN Rongfu, DING Ran, et al. Multi-time scale reactive power and voltage optimization of distribution network considering photovoltaic multi state regulation capability[J]. Electric Power, 2022, 55 (3): 105- 114.
|
| 4 |
白晶, 金广厚, 孙鹤林, 等. 高渗透光伏配电网第三方主体调压辅助服务补偿与获取[J]. 中国电力, 2023, 56 (4): 95- 103.
|
|
BAI Jing, JIN Guanghou, SUN Helin, et al. Third-party entity voltage regulation ancillary service compensation and procurement in distribution networks with high-penetration PV[J]. Electric Power, 2023, 56 (4): 95- 103.
|
| 5 |
黄南天, 郭玉, 赵暄远. 计及辐照区间划分的含光伏电源配电网源-荷联合场景生成[J]. 东北电力大学学报, 2023, 43 (5): 78- 84.
|
|
HUANG Nantian, GUO Yu, ZHAO Xuanyuan. Combined source-load scenario generation for PV-containing distribution networks with calculation and irradiation interval classification[J]. Journal of Northeast Electric Power University, 2023, 43 (5): 78- 84.
|
| 6 |
祁晓婧. 计及不确定性的主动配电网有功无功联合优化调度技术研究[D]. 南京: 东南大学, 2019.
|
|
QI Xiaojing. Research on joint optimal dispatch technology of active and reactive power in active distribution networks considering uncertainty[D]. Nanjing: Southeast University, 2019.
|
| 7 |
王耀翔, 戴朝波, 杨志昌, 等. 考虑风电机组无功潜力的风电场无功电压控制策略[J]. 电力系统保护与控制, 2022, 50 (24): 83- 90.
|
|
WANG Yaoxiang, DAI Chaobo, YANG Zhichang, et al. Voltage control strategy for a wind farm considering the reactive capability of DFIGs[J]. Power System Protection and Control, 2022, 50 (24): 83- 90.
|
| 8 |
马君亮, 王智冬, 张述铭. 考虑县域光伏潜力评估的源网荷储协同规划[J]. 东北电力大学学报, 2023, 43 (3): 82- 90.
|
|
MA Junliang, WANG Zhidong, ZHANG Shuming. Collaborative planning of source-grid-load-storage considering County PV potential assessment[J]. Journal of Northeast Electric Power University, 2023, 43 (3): 82- 90.
|
| 9 |
马跃, 孟润泉, 魏斌, 等. 考虑阶梯式碳交易机制的微电网两阶段鲁棒优化调度[J]. 电力系统保护与控制, 2023, 51 (10): 22- 33.
|
|
MA Yue, MENG Runquan, WEI Bin, et al. Two-stage robust optimal scheduling of a microgrid with a stepped carbon trading mechanism[J]. Power System Protection and Control, 2023, 51 (10): 22- 33.
|
| 10 |
孙端航, 李本新. 考虑风电不确定性的电网状态检修策略[J]. 东北电力大学学报, 2023, 43 (4): 65- 73.
|
|
SUN Duanhang, LI Benxin. Condition-based maintenance scheduling for power transmission system considering wind power uncertainty[J]. Journal of Northeast Electric Power University, 2023, 43 (4): 65- 73.
|
| 11 |
朱建昆, 高红均, 贺帅佳, 等. 考虑VSC与光-储-充协同配置的交直流混合配电网规划[J]. 智慧电力, 2023, 51 (11): 7- 14.
|
|
ZHU Jiankun, GAO Hongjun, HE Shuaijia, et al. AC-DC hybrid distribution network planning considering VSC and photovoltaic-storage-charging coordinated configuration[J]. Smart Power, 2023, 51 (11): 7- 14.
|
| 12 |
李笑竹, 王维庆. 基于贝叶斯理论的分布鲁棒优化在储能配置上的应用[J]. 电网技术, 2022, 46 (10): 4001- 4011.
|
|
LI Xiaozhu, WANG Weiqing. Application of distributed robust optimization based on bayesian theory in allocation of energy storage[J]. Power System Technology, 2022, 46 (10): 4001- 4011.
|
| 13 |
徐澄莹, 朱旭, 窦真兰, 等. 基于数据驱动鲁棒优化的用户侧综合能源舱低碳规划[J]. 电力建设, 2022, 43 (12): 27- 36.
|
|
XU Chengying, ZHU Xu, DOU Zhenlan, et al. Research on low carbon planning based on data driven robust optimization for user-side integrated energy module[J]. Electric Power Construction, 2022, 43 (12): 27- 36.
|
| 14 |
KOU P, LIANG D L, WANG C, et al. Safe deep reinforcement learning-based constrained optimal control scheme for active distribution networks[J]. Applied Energy, 2020, 264, 114772.
|
| 15 |
CHU Y F, WEI Z N, FANG X C, et al. A multiagent federated reinforcement learning approach for plug-In electric vehicle fleet charging coordination in a residential community[J]. IEEE Access, 2022, 10, 98535- 98548.
|
| 16 |
戴武昌, 刘艾冬, 申鑫, 等. 基于MADDPG算法的家用电动汽车集群充放电行为在线优化[J]. 东北电力大学学报, 2021, 41 (5): 80- 89.
|
|
DAI Wuchang, LIU Aidong, SHEN Xin, et al. Online optimization of charging and discharging behavior of household electric vehicle cluster based on MADDPG algorithm[J]. Journal of Northeast Electric Power University, 2021, 41 (5): 80- 89.
|
| 17 |
HOU S R, SALAZAR E M, VERGARA P P, et al. Performance comparison of deep RL algorithms for energy systems optimal scheduling[C]//2022 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe). Novi Sad, Serbia. IEEE, 2022: 1–6.
|
| 18 |
LIU H T, WU W C. Two-stage deep reinforcement learning for inverter-based volt-VAR control in active distribution networks[J]. IEEE Transactions on Smart Grid, 2021, 12 (3): 2037- 2047.
|
| 19 |
GAO Y Q, WANG W, SHI J, et al. Batch-constrained reinforcement learning for dynamic distribution network reconfiguration[J]. IEEE Transactions on Smart Grid, 2020, 11 (6): 5357- 5369.
|
| 20 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//4th International Conference on Learning Representations. San Juan, 2016.
|
| 21 |
LI H P, HE H B. Learning to operate distribution networks with safe deep reinforcement learning[J]. IEEE Transactions on Smart Grid, 2022, 13 (3): 1860- 1872.
|
| 22 |
季颖, 王建辉. 基于深度强化学习的微电网在线优化调度[J]. 控制与决策, 2022, 37 (7): 1675- 1684.
|
|
JI Ying, WANG Jianhui. Microgrid online optimal dispatch based on deep reinforcement learning[J]. Control and Decision-making, 2022, 37 (7): 1675- 1684.
|
| 23 |
兰飞, 林立成, 黎静华. 基于改进变分模态分解和信息融合的故障选线[J]. 东北电力大学学报, 2022, 42 (5): 1- 14.
|
|
LAN Fei, LIN Licheng, LI Jinghua. Fault line selection based on improved variational mode decomposition and information fusion[J]. Journal of Northeast Electric Power University, 2022, 42 (5): 1- 14.
|
| 24 |
DING Y, LAVAEI J. Provably efficient primal-dual reinforcement learning for cmdps with non-stationary objectives and constraints[C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 37(6): 7396–7404.
|
| 25 |
PASZKE A, GROSS S, MASSA F, et al. Pytorch: an imperative style, high-performance deep learning library[J]. Advances in Neural Information Processing Systems, 2019, 32, 8024- 8035.
|